��The Universe is made of stories, not of atoms.” -Muriel Rukeyser
Last time, I discussed why we offer suggested locations to teleport to, and the 5 W’s of the user interaction for suggestions. This time I’ll discuss how we do that, with some level of technical specificity.
Nouns and Stories
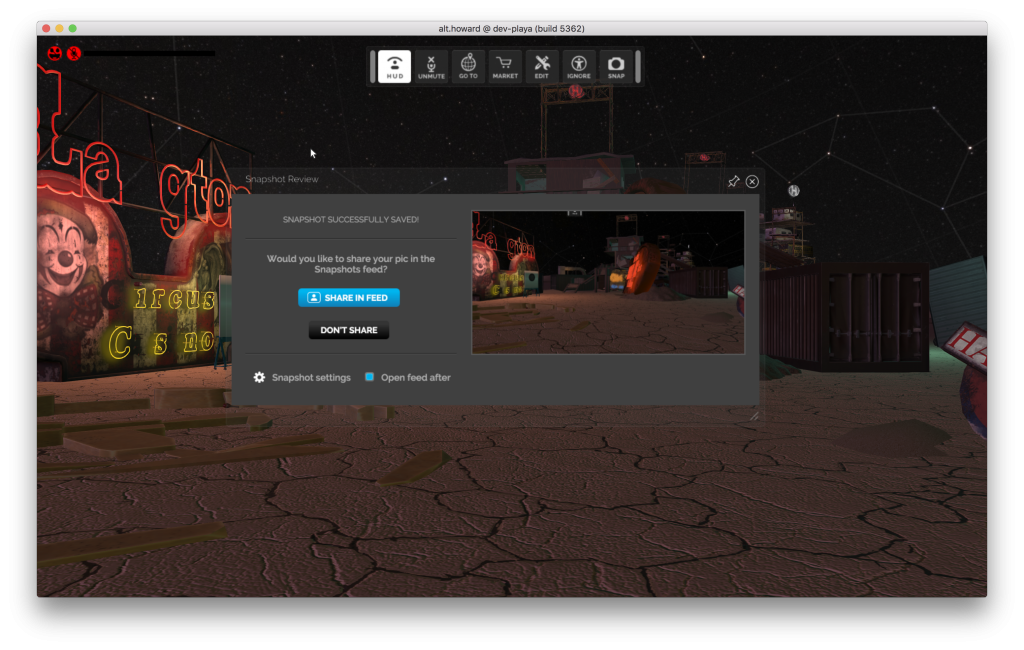
Each suggestion is a compact “story” of the form: User => Action => Object. Facebook calls these “User Stories” (perhaps after product management language), and linguists refer to “SVO” sentences. For example, Howard => snapshot => Playa, which we display as “Howard took a snapshot in Playa”. In this case Playa is a Place in-world. The Story also records the specific position/orientation where the picture was taken, and the picture itself. Each story has a unique page generated from this information, giving the picture, description, a link to the location in world, and the usual buttons to share it on external social media. Because of the metadata on the page, the story will be displayed in external media with the picture and text, and clicking on the story within an external feed will bring them to this page.
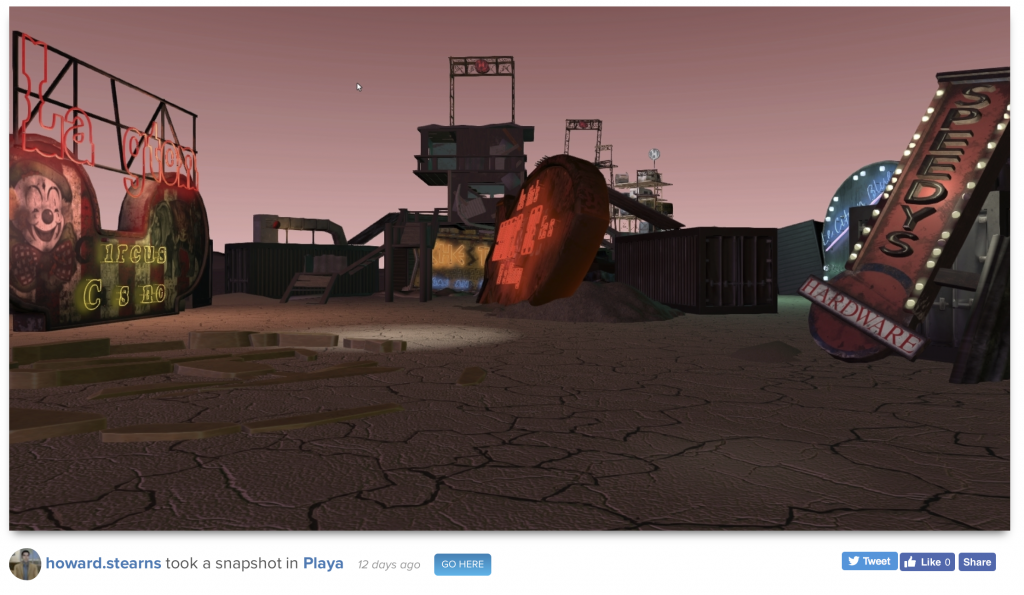
The User is, of course, the creator of the story. The user has a page, too, which shows some of their user stories, and any picture and description they have chosen to share publicly. If allowed, there’s a link to go directly to that user, wherever they are.
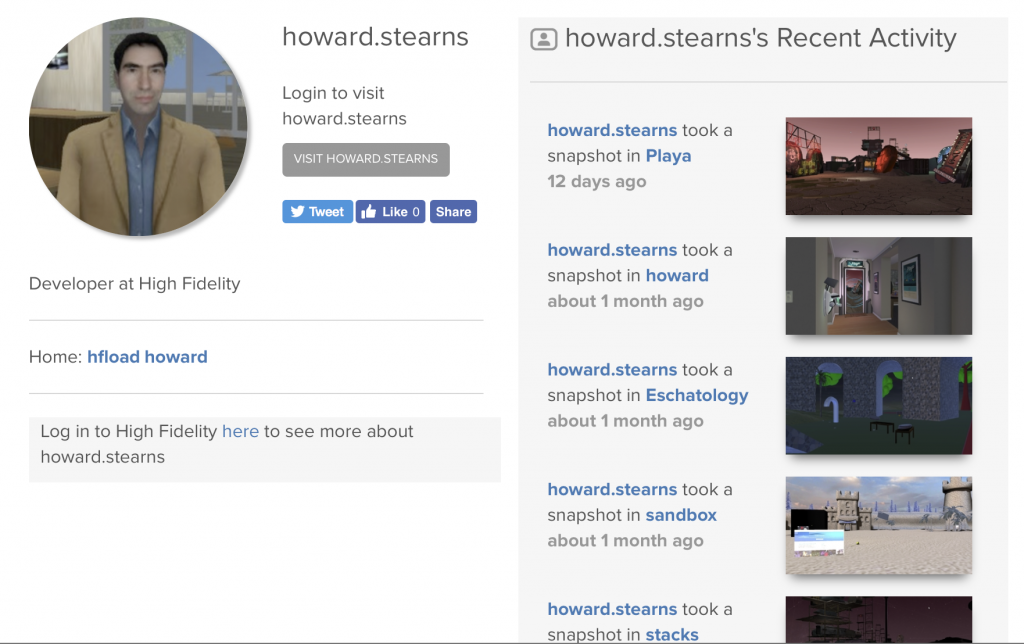
For our current snapshot and concurrency user stories, the Object is the public Place by which the user entered. More generally, it could be any User, Place, or (e.g., marketplace) Thing. These also get their own pages.
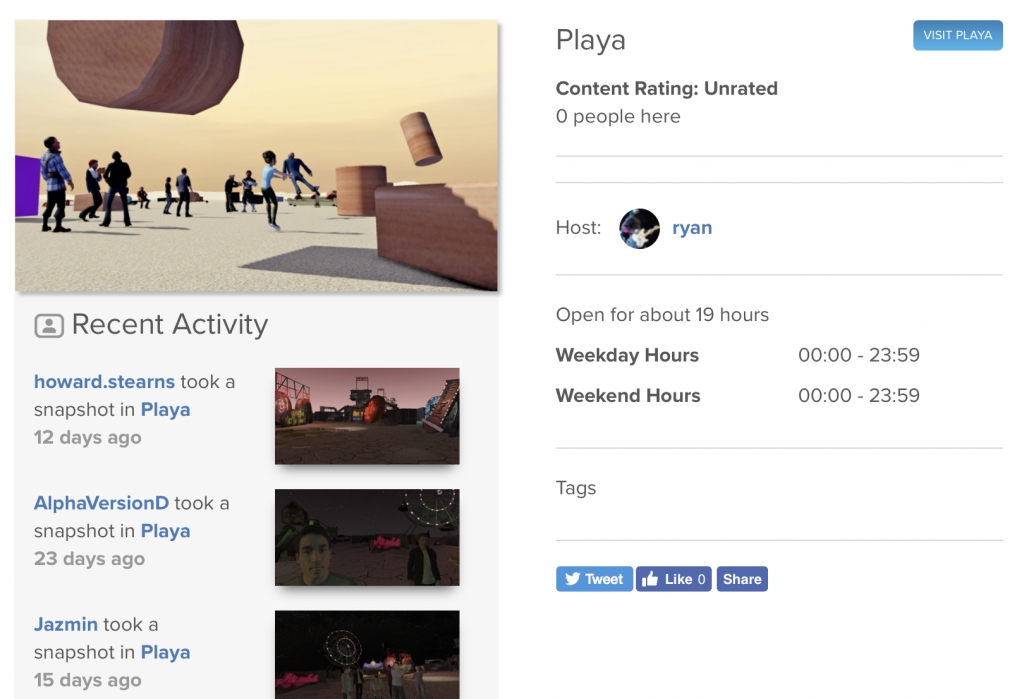
The “feed” is then simply an in-world list of such Stories.
Control
Analogously to any computer on a network and registering with ICANN, a High Fidelity user may create places at an IP address or even a free temporary place name, or they can register a non-temporary name. Places are shown as suggestions to a user only when they are explicitly named places, with no entry restrictions, matching the user’s protocol version. (When we eventually have individual user feeds, we could consider a place to be shareable to a particular user if that logged in user can enter, rather than only those with no restrictions.)
Snapshots are shown only when explicitly shared by a logged-in user, in a shareable place.
Scale
At metaverse scale, there could be trillions of people, places, things, and stories about them. That’s tough to implement, and tough for users to make use of the firehose of info. But now there isn’t that many, and we don’t want to fracture our initial pioneer community into isolated feeds-of-one. So we are designing for scale, but building iteratively, initially using our existing database services and infrastructure. Let’s look first at the design for scale:
First, all the atoms of this universe – people, places, things, and stories – are each small bags of properties that are always looked up by a unique internal identifier. (The system needs to know that identifier, but users don’t.) We will be able to store them as “JSON documents” in a “big file system” or Distributed Hash Table. This means they can be individually read or written quickly and without �locking� other documents, even when there are trillions of such small �documents� spread over many machines (in a data center or even distributed on participating user machines). We don�t traverse or search through these documents. Instead, every reason we have for looking one up is covered by something else that directly has that document�s identifier.
(There are a few small exceptions to the idea that we don�t have to lock any document other than the one being looked up. For example, if we want to record that one user is �following� another, that has to be done quite carefully to ensure that a chain of people can all decide to follow the next at the same time.)
There are also lists of document identifiers that can be very long. �For example, a global feed of all Stories would have to find each Story one or more at a time, in some order. (Think of an �infinitely scrollable� list of Stories.) One efficient way to do that is to have the requesting client grab a more manageable �page� of perhaps 100 identifiers, and then look up the document on however many of those fit on the current display. As the user scrolls, more are looked up. When the user exhausts that set of identifiers, the next set is fetched. Thus such �long paged lists� can be implemented as a JSON document that contains an ordered array of a number of other document identifiers, plus the identifier for the next �page�. Again, each fetch just requires one more document retrieval, looked up directly by identifier. The global feed object is just a document that points to the identifier of the �page� that is currently first. �Individual feeds, pre-filtered interest lists, and other features can be implemented as similar long paged lists.
However, at current scale, we don’t need any of that yet. For the support of other aspects of High Fidelity, we currently have a conventional single-machine Rails Web server, connected to a conventional Postgres relational database. The Users, Places, and Stories are each represented as a data table, indexed by identifier. �The feed is a sorted query of Stories.
We expect to be able to go for quite some time with this setup, using conventional scaling techniques of bigger machines, distributed databases, and so forth. �For example, we could go to individual feeds as soon as there are enough users for a global feed to be overwhelming, and enough of your online friends to have High Fidelity such that a personal feed is interesting, This can be done within the current architecture, and would allow a larger volume of Stories to be simultaneous added, retrieved, scored, and sorted quickly. �Note, though, that we would really like all users to be offered suggestions — even when they choose to remain anonymous by not logging in, or don�t yet have enough experience to choose who or what to follow. Thus a global feed will still have to work.
Scoring
We don�t simply list each Story with the most recent ones first. If there�s a lot of activity someplace, we want to clearly show that up front without a lot of scrolling, or a lot of reading of place or user names. For example, a cluster of snapshots in the feed can often make it quite clear what kind of activity is happening, but we want the ordering mechanism to work across mixes of Stories that haven�t even been conceived of yet.
Our ordering doesn�t have to be perfect – there is no �Right Answer�. Our only duty here is to be interesting. We keep the list current by giving each Story a score, which decays over time. The feed shows Stories with the highest scores first. Because the scores decay over time, the feed will generally have newer items first, unless the story score started off quite high, or something bumped the score higher since creation. For example, if someone shares a Story in Facebook, we could bump up the score of the Story — although we don�t do that yet.
Although we don�t display ordered lists of Users or Places, we do keep scores for them. These scores are used in computing the scores of Stories. �For example, a snapshot has a higher initial score if it is taken in a high scoring Place, or by a high scoring User. This gives stories an effect like Google�s page ranking, in which pages with lots of links to them are listed before more obscure pages.
To keep it simple, each item only gets one score. While you and I might eventually have distinct feeds that list different sets of items, an item that appears in your list and my list still just has one score rather than a score-for-you and different score-for-me. (Again, we want this to work for billions of users on trillions of stories.)
To compute a time-decayed score, we store a score number and the timestamp at which it was last updated. �When we read an individual score (e.g., from a Place or User in order to determine the initial score of a snapshot taken in that Place by that User), we update the score and timestamp. �This fits our scaling goals because only a small finite number of scores are updated at a time. For example, when the score of a Place changes, we do not go back and update the scores of all the thousands or millions of Stories associated with that Place. The tricky part is in sorting the Stories by score, because sorting is very expensive on big sets of items. Eventually, when we maintain our �long paged lists� as described above, we will re-sort only the top few pages when a new Story is created. (It doesn�t really matter if a Story appears on several pages, and we can have the client filter out the small numbers of duplicates as a user scrolls to new pages of stories.) For now, though, in our Rails implementation, a new snapshot causes us to update the time-decayed score for each snapshot in order, starting from what was highest scoring. Once a story�s score falls below a certain threshold, we stop updating. �Therefore, we�re only ever updating the scores of a few days worth of activity.
Here are our actual scoring rules at the time I write this. There�s every chance that the rules will be different by the time you read this, and like most crowd-curation sites on the Web, we don�t particularly plan to update the details publicly. But I do want to present this as a specific example of the kinds of things that affect the ordering.
- We only show Stories in a score-ordered list. (The Feed.) However, we do score Users and Places, because their scores are used for snapshots. We do this based on the opt-outable “activity” reporting:
- Moving in the last 10 seconds bumps the User’s score by 0.02.
- Entering a place bumps the Place’s score by 0.2.
- Snapshot Stories have an initial score that is the decayed average of the User and Place – but a minimum of 1.
- Concurrency Stories get reset whenever anyone enters or leaves, to a value of nUsersRemaining/2 + 1.
- All scores have a half-life of 3 days on the part of the score up to 2, and 2 hours for the portion over 2. Thus a flurry of activity might spike a user or place score for a few hours, and then settle into the “normal high” of 2. �This �anti-windup� behavior allows things to settle into normal pretty quickly, while still recognizing flash mob activity.
For example, under these rules, one needs to move for about 3:20 minutes / day to keep your score nominally high (2.0). �More activity will help the snapshots you create during the activity, but only for a while, and snapshots the next day will only have an nominally high effect.
As another example of current rules, an event with 25 people will bump a place score by 5:
- If it started at 2, it will back down to 4.5 in two hours, 2.5 in six hours, and back to 2 in 10 hours.
- If it started at 0, it we be at 3.5 in two hours, and then roughly as above.
Search
We currently search the filter on the client, filtering from the 100 highest scoring results that we receive from the server. Each typed word appears exactly (except for case) within a word of the description or other metadata (such as the word ‘concurrency’ for a concurrency story). There is no autocorrect nor autocomplete, nor pluralization nor stemming. So, typing “stacks concurrency” will show only the concurrency story for the place named stacks. “howard.stearns snapshot” will show only snapshots taken by me.
When the volume of data gets large enough, I expect we’ll add server-side searching, with tags.
Conclusion
We feel that by using the “wisdom of crowds” to score and order suggestions of what to do, we can:
- Make it easy to find things you are interested in
- Make it easy to share things you like
- Allow you to affirm others� activities and have yours affirmed
- Connect people quickly
- Create atomic assets that can be shared on various mediums
In doing so, we hope to create a better experience by bringing users to the great people and content that are already there, and encourage more great content development.



